









Markov Chains – Random Text Generation
This semester I am taking a course in High Performance Computing where I get to work with multi-core systems like computing clusters and graphics cards. For my final project I decided to develop a random text generator and see if I could speed it up.
A popular method of generating random text (that is grammatically correct) is using Markov chains.
What is a Markov chain?
A Markov chain is a state machine. The next output depends on the current state. So if you were generating random text, the word to follow would depend on the current word(s). A way to model real speech would be to parse some text and to make a table of prefixes and suffixes. So for example, for the prefix “how are you”, the possible suffixes might be “feeling?”, “doing?”, “able” depending on the context.
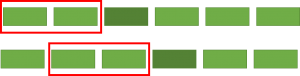
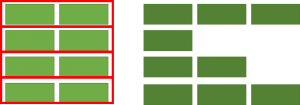
Once a table is built, you can randomly walk over the table to generate text that more or less follows the syntax of the input text. Let’s say you were making a Markov chain of order 2 i.e. prefixes of 2 words. First you’d select a random prefix from the table. That prefix would have a list of possible suffixes. You randomly choose one. Now you have three words printed out: the prefix (2 words) and the suffix (1 word). To find out the next word, you simply create a new prefix consisting of the last word in the previous prefix and your current suffix. So if you chose “The quick” as a prefix, and you got “brown” as a suffix, the next prefix would be “quick brown”. That would yield another word from which you’d make another prefix and so on.
Speeding up the process
One way to speed up the process is to use multiple threads to create the chain from a body of text. Each thread parses a certain section of the input, creates a table, and merges it with the universal Markov chain.
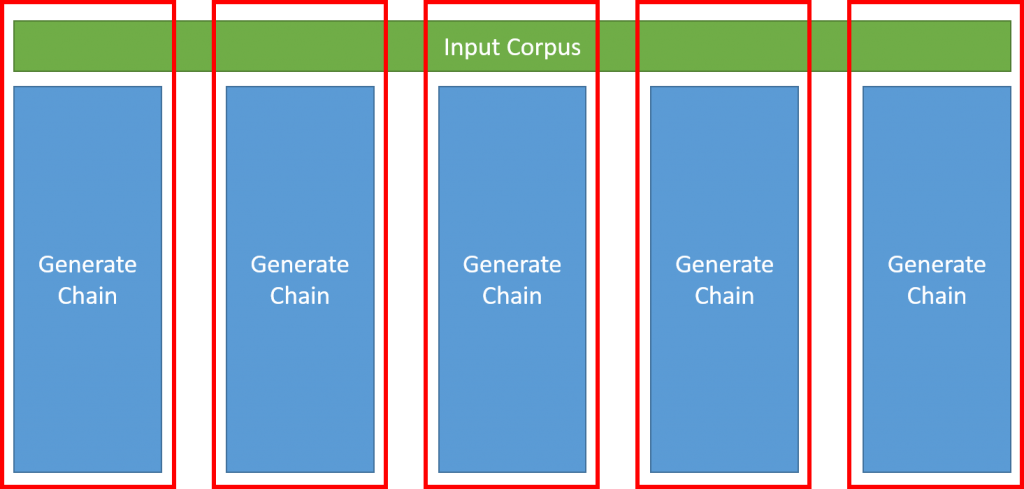
However chain generation is only one part of the process which includes other tasks that happen serially. And given that chain generation takes linear time with respect to the input, I was not expecting a dramatic speed-up by parallelizing code.
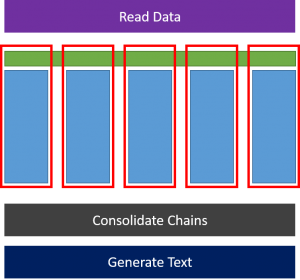
I implemented the process in my first ever complete C++ project. I used p_threads for parallel implementation. I could have used multiple processes, but the cost of inter-process communication was too much for O(n) process, I thought. I tested out my code on War and Peace by Leo Tolstoy with different prefix lengths and threads. The speed-ups were decent but not spectacular:
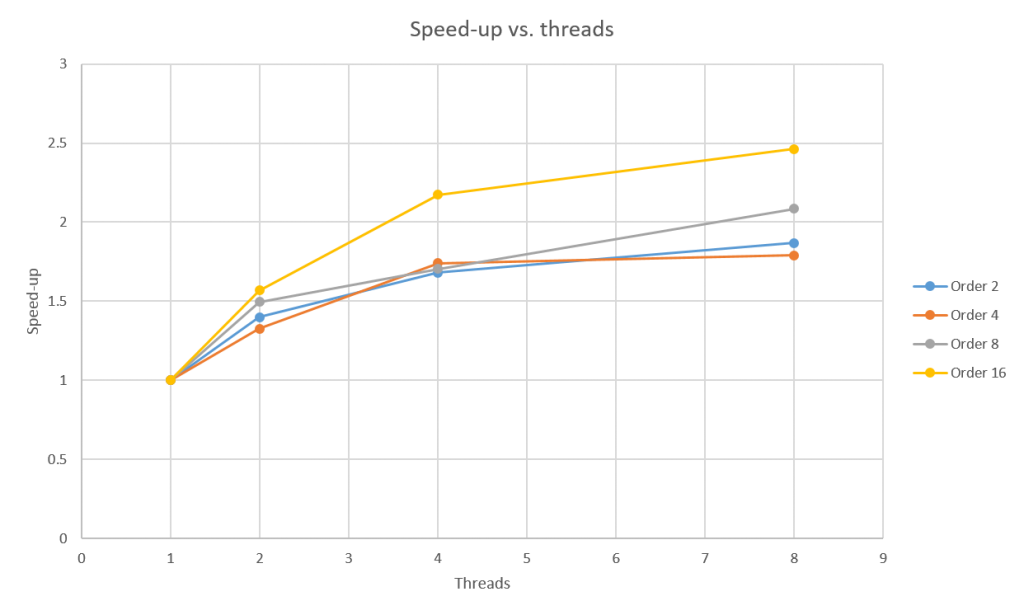
The source code can be found here.