ChatGPT x Tennis - a weekend hacking project
I like love playing tennis. One tennis event I go to is very popular. It gets posted online a week ahead, at a random time late in the morning. Within an hour of the post going online, all spots are taken up. I want to play every week.
My current solution is to rely on a carefully cultivated clique of confidants who will text me when the next event is up.
It works sometimes.
Problem & Approach
I want it to work every time. I want to be notified as soon as the event is up so I can put my name in. Now, the website the event is hosted on has a paid Pro subscription. It will notify me when events are up. They also have a paid developer API which I can use to automatically RSVP to an event.
But why spend 5 dollas on the Pro or Developer features? I can save that money for my retirement account, and instead spend 5 hours of my PhD-having billable hours on solving this. Right?
This was my approach:
- Extraction: parse website for my event information
- When the desired event is up, notify me with the link promptly
- Once I get the link, I will manually add myself to the event
- I could use libraries like puppeteer to automate logging in an clicking on “Attend” button, but I figured that was too much work
- Run (1,2) only during fixed times every week
Extraction
Attempt 1 - scraping
My first thought was to write a website scraper that can parse the DOM (document object model) for the event card. I faintly remember being able to use beautifulsoup4 for that. But, I’d forgotten. So, I asked ChatGPT for help:
Me: What is python code to get HTML code of a web page?
ChatGPT: You can use therequestslibrary in Python to retrieve the HTML code of a web page. Here’s an example of how you can do it:
| |
Me: How to parse this HTML to find a div element containing the text “TEXT”
ChatGPT: To parse HTML and find a<div>element containing the text “TEXT,” you can use the BeautifulSoup library in Python. Here’s an example that builds upon the previous code snippet:
| |
Me: How to find a div element only using part of the text? For example, if the div contains “This is text”, how to find that div using only “is text” for query
ChatGPT: To find a<div>element based on a partial text match, you can use a lambda function with thetextparameter in BeautifulSoup. Here’s an updated example that demonstrates how to achieve this:
| |
Me: How to find multiple div elements with the same text?
ChatGPT: To find multiple<div>elements with the same text, you can use thefind_all()method in BeautifulSoup. Here’s an example that demonstrates how to accomplish this:
| |
So now, my code looks like this:
| |
There are two issues. (1) This returns the <a> element containing the link to my event. It is fine, but I will need to parse the HTML to get more details (for e.g. whether it is cancelled, and how many are already signed up to go etc.)
And (2). I cannot find my event.
Attempt 2 - querying
See, the website’s DOM is not static. When I load the page, it only shows the next 10 events. Scrolling to the page end triggers more events to load. When I look a week ahead, I usually have to scroll to the end of the page once, wait for more events to load, and then find the link to my event.
Hmm. So there are network requests being made which dynamically load new events. Can I get data directly from them?
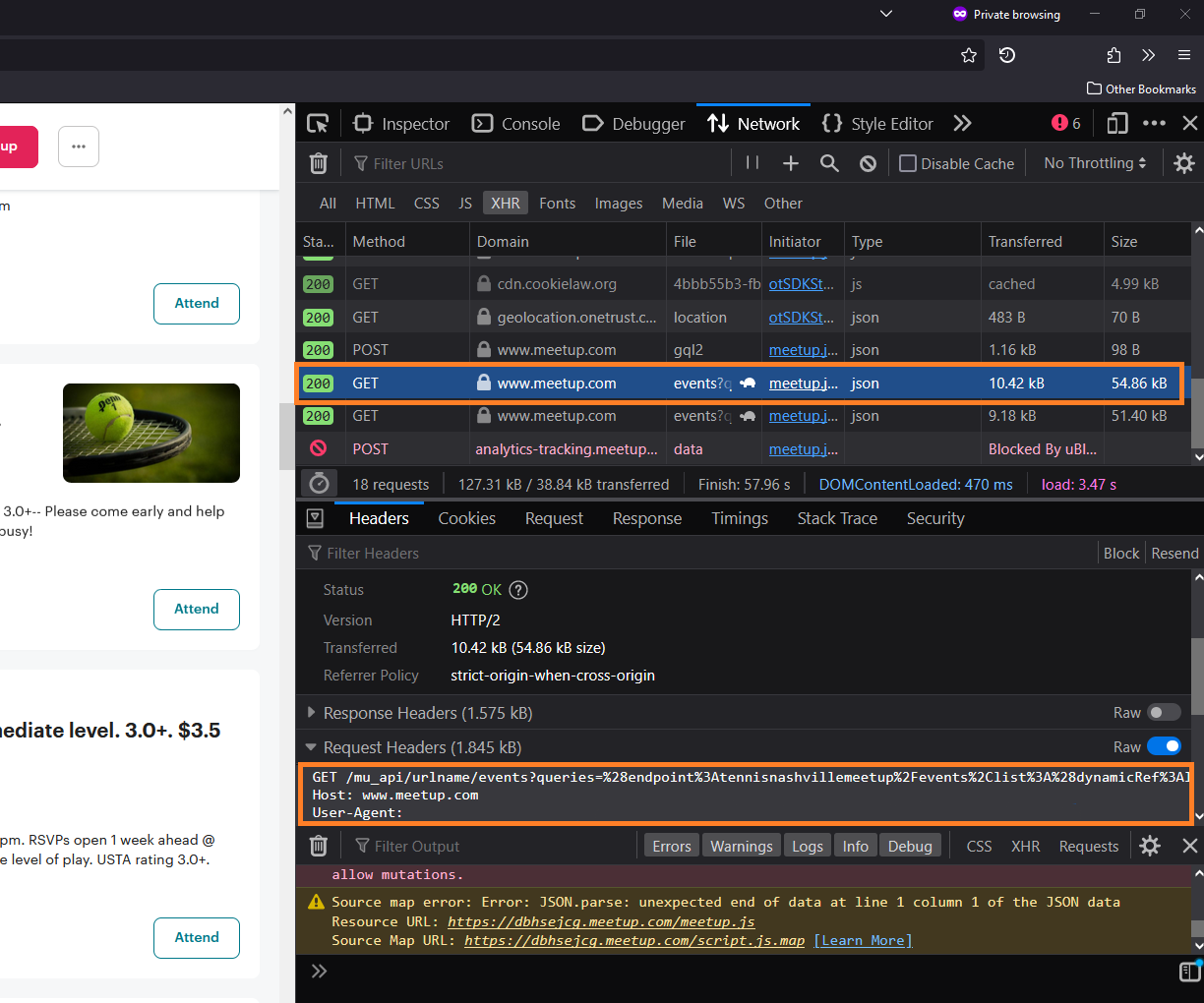
Yes, I can! By opening the developer console (Ctrl+Shift+I), refreshing the page, and scrolling until a load of events is triggered, I can pinpoint the GET request being made. The response is a JSON object, which I can parse using python’s json.loads() function.
The GET request is made with several parameters. They include the time window and the fields in the requested payload. Therefore, I can only ask for the events during the time I am interested in, and only the information I need. This will save the website server unnecessary bandwidth.
So now, my code looks like this:
| |
Notification
Ok. I have the list of events, and the event I am interested in. Fine. How do I notify myself when that new event is up?
Attempt 1 - Tasker
I note that I am usually at home after tennis, during the time when this goes up. I can set up a local server which will serve me this information.
Alright, I can use python’s build-in http.server. I’ve dabble with that before; I can make it work. But, how do I actually notify myself that there is new information available? I can make my phone query the server at intervals until I have the event link.
I can use Tasker! I had paid for this application on a whim using my Google Opinion Rewards dollas. Now is the time to shine! Tasker is an application that “performs tasks (sets of actions) based on contexts (application, time, date, location, event, gesture) in user-defined profiles or in clickable or timer home screen widgets.”
So, I can set up a Tasker Action to query my local server at a certain interval and pop up a widget with the resulting information. The images below show the task setup, and how the widget looks:
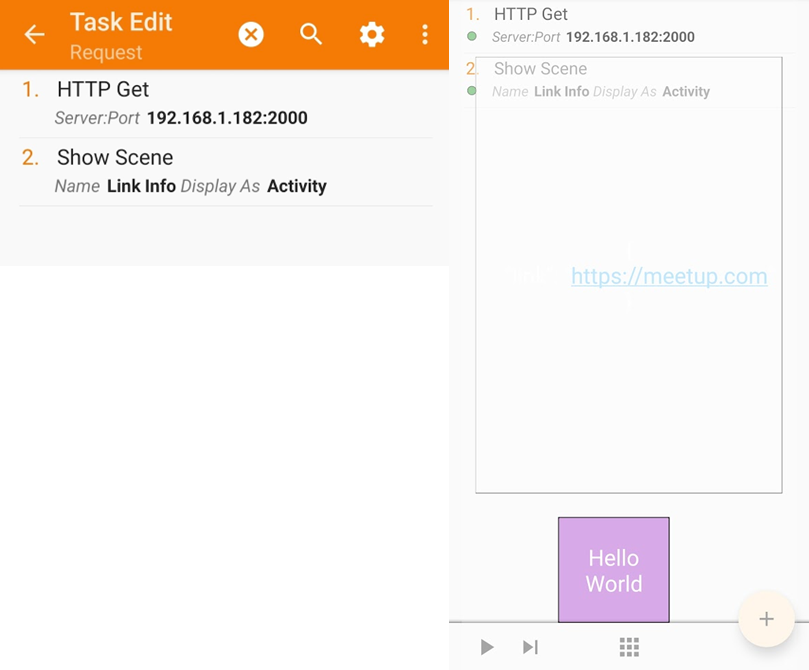
Now, the server. I ask ChatGPT for a script to run a HTTP server and serve a string response. Some changes later, I get the following snippet. The server will run for only one request. It will serve the URL of the event RSVP page, and then quit.
| |
I am feeling not quite entirely pleased. This setup is clunky. I have to run a server and I have to be on my home network and I have to set up an Android widget to notify me.
Attempt 2 - Email
Why not just use email? I won’t be tied to my home network. And, my mobile email client already knows to send me notifications for new messages.
I know I can use python’s smtp and email libraries to connect to email servers and compose messages. I think connecting to a Gmail account may be tricky. I have two factor authentication set up. A few web searches later, I know the answer. Google lets me set up an app-specific password. Consider it an API key. I can use that to log into my email and send myself a message.
| |
Great! I now have two options to get my event information. Some clobbering later, I have combined everything into a python script. I won’t repeat myself, but the pseudo code looks like this:
Use python's argparse.ArgumentParser to set up some command line options for:
event search query
query interval
notification method (email/server)
stop time
while not stop time:
event = get_event(search query)
if not event:
sleep for query interval
if event:
if notification via email:
send_email(event)
else:
make_server(event)
Automation
Finally, automation. How do I make the script run at specific times of the week? I will use Cron jobs. Cron is a handy utility on GNU/Linux which can run commands at intervals. All it takes is to specify in the crontabs file as:
| |
This entry makes python myscript.py run on every Saturday at 11am. I set the Gmail application password and email addresses as environment variables. So first, I run my user’s .profile, before my python script is able to run.
I deploy this on a Raspberry Pi 3 that I’ve been running as a little lab server.
Et viola! I test it with an event and I get an email!
Thoughts
This project was the brainchild of my desire to attend my favorite tennis event. I used it to test out instruction-tuned large language models as productivity aids. The results were good, but with a grain of salt.
On one hand, I like that I am able to scaffold the code I eventually want written. Sometimes, ChatGPT will use libraries I haven’t heard of. Sometimes, it will suggest a course of action I hadn’t thought of. (For example, it used the sched library to schedule the HTTP server shutdown after it had served the event URL.) These were all learning experiences.
Ultimately, however, I am the conductor. I was responsible for orchestrating my solution. ChatGPT distinguished itself helping me scrape the website for text. But, it was my experience with wrangling network requests that helped me pivot towards my second attempt. Similarly, ChatGPT happily wrote away the perfect HTTP server. But, it was my evaluation of pros/cons of the server-android widget setup that let me to a more elegant email-based solution.
≡
Ibrahim Ahmed